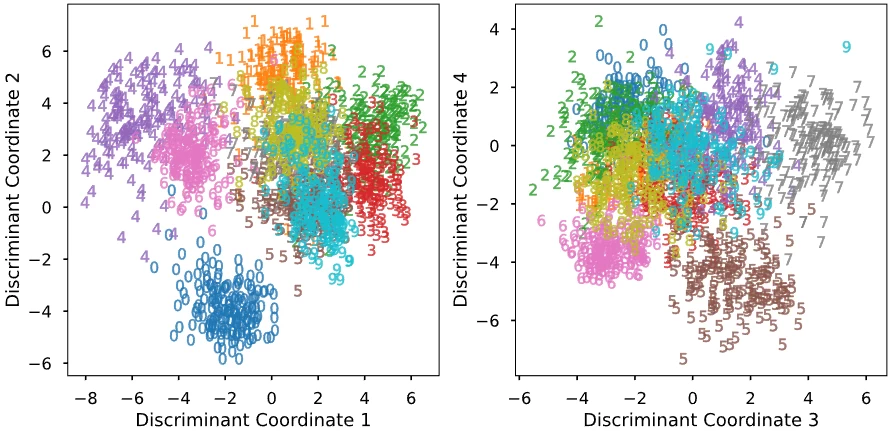
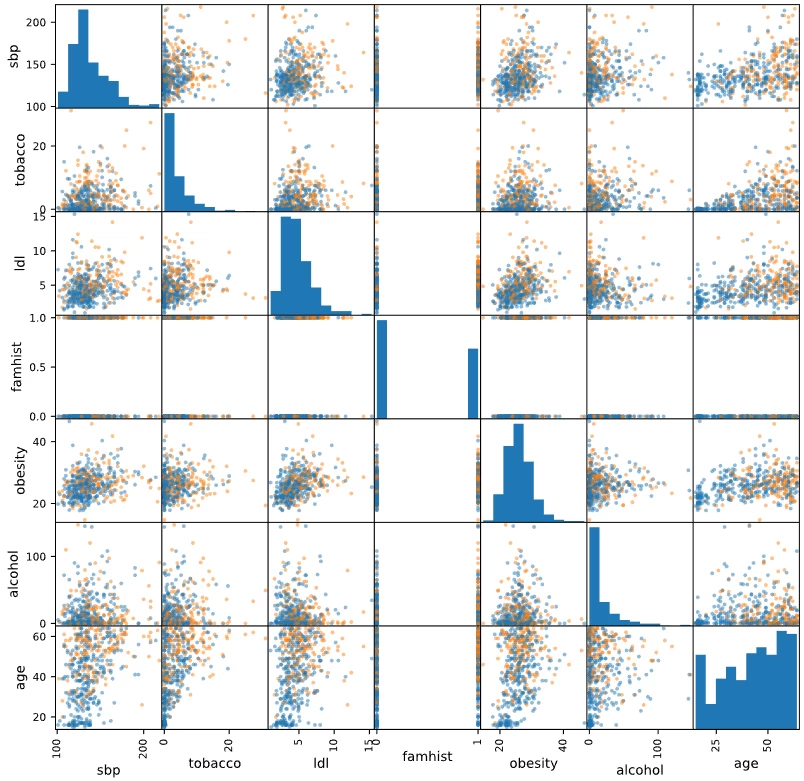
orem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt ut labore et dolore magna
m ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt ut
$$Y_3 = [0, 0, 1, 0, 0]$$
rem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod temp
m ipsum $\mathcal{G}$ ipsu $K$ ipsum dolor sit amet m c $K$ orem ipsum dolor $Y_k$ m $k=1,\cdots,K$ m with
$$ Y_k = 1 \text{ if } G = k \text{ else } 0. $$
Lorem ipsum dolor sit amet, consectetur a $Y=(Y_1,\cdots,Y_k)$ Lorem ipsu $N$ orem ipsum dolor sit amet, consectetur a $N\times K$ em ipsum dolor sit amet, consectetur $\mathbf{Y}$ em ipsum dolor sit amet $0$ Lorem i $1$ m ipsum dolor sit amet, consectetu $1$ L
ipsum dolor
$$ Y = \begin{bmatrix} 1 & 0 & 0 & 0 & 0 \\ 0 & 1 & 0 & 0 & 0 \\ & & \vdots & & \\ 0 & 0 & 0 & 0 & 1 \end{bmatrix} $$
m ipsum dolor sit amet, consectetur adipiscing elit $\mathbf{Y}$ em ipsum dolor sit amet, consectetur adi
\begin{equation} \hat{\mathbf{Y}} = \mathbf{X}\left(\mathbf{X}^T\mathbf{X}\right)^{-1}\mathbf{X}^T\mathbf{Y} = \mathbf{X}\hat{\mathbf{B}}. \end{equation}
em ipsum dolor sit amet, consectetur adipiscing elit, sed do eius $\mathbf{y}_k$ orem ipsum dol $(p+1)\times K$ orem ipsum dolor sit $\hat{\mathbf{B}} = \left(\mathbf{X}^T\mathbf{X}\right)^{-1}\mathbf{X}^T\mathbf{Y}$ ipsum $\mathbf{X}$ Lorem ipsum dolor sit amet $p+1$ m ipsum dolor sit amet, consectetur $1$ Lorem ipsum dolor sit
ipsum dolor sit amet, consec $x$ Lorem ipsum dolor sit amet
- m ipsum dolor sit amet, co $\hat{f}(x)^T = (1, x^T)^T\hat{\mathbf{B}}$ orem $K$ m ipsum
- rem ipsum dolor sit amet, consectetur adipiscing elit, se
\begin{equation} \hat{G}(x) = \arg\max_{k\in\mathcal{G}} \hat{f}_k(x). \end{equation}
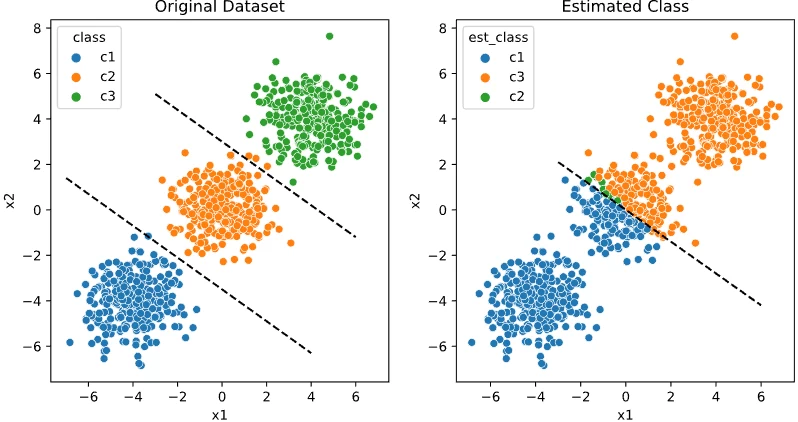
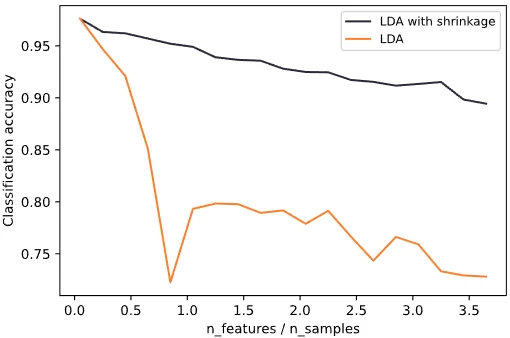
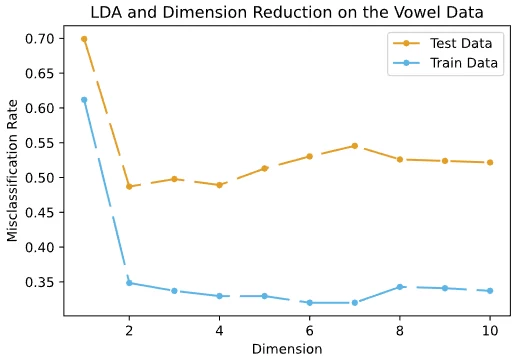
Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt ut labore et dolore magna al
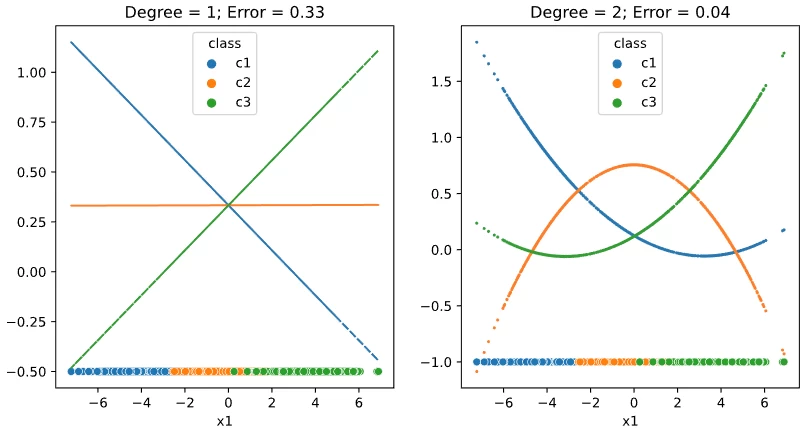
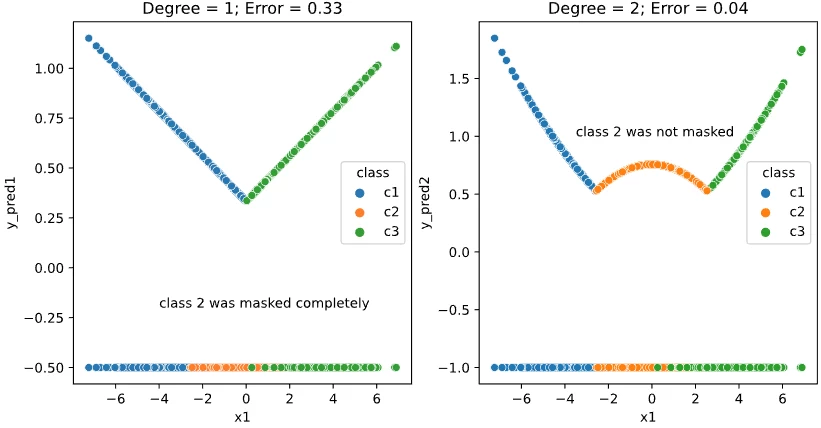
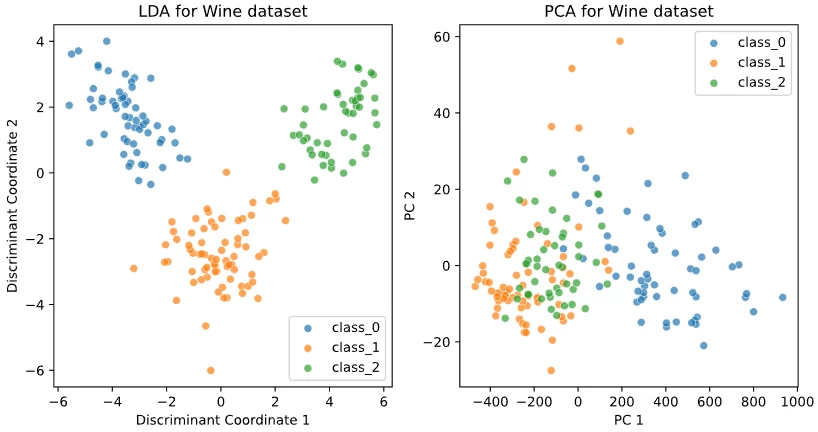
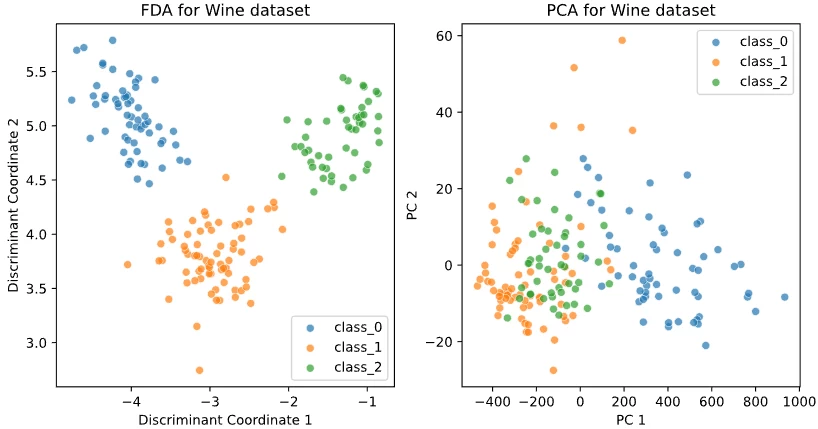
Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmo $K\ge 3$ em ipsum dolor sit amet, con $K$ orem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt ut labore et dolore magna aliqua. Ut enim ad minim veniam, quis nostrud $K=3$ rem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt ut labore et dolore magna aliqu